Abstract
Audio intent detection is a crucial component of modern voice assistants and speech recognition systems. This article explores the application of Mel-Frequency Cepstral Coefficients (MFCC) in audio processing for intent detection, covering feature extraction techniques, neural network architectures, and practical implementation strategies using TensorFlow and Keras.
Introduction
Intent detection from audio signals involves understanding the user's intention behind spoken commands or queries. This task is fundamental to voice-controlled systems, smart home devices, and conversational AI applications. The challenge lies in extracting meaningful features from raw audio signals and training models that can accurately classify user intents.
Understanding MFCC Features
What are MFCCs?
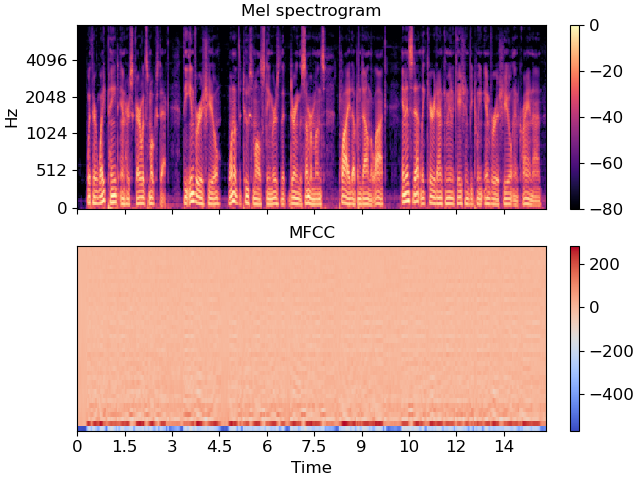
Mel-Frequency Cepstral Coefficients (MFCC) are a representation of the short-term power spectrum of a sound, based on a linear cosine transform of a log power spectrum on a nonlinear mel scale of frequency. They are widely used in speech recognition because they capture the characteristics of human speech production.
Why MFCCs for Audio Processing?
MFCCs offer several advantages for audio intent detection:
- Compact Representation: Reduce dimensionality while preserving important information
- Human Auditory System Modeling: Based on how humans perceive sound
- Robustness: Less sensitive to noise compared to raw audio
- Computational Efficiency: Fast to compute and process
Feature Extraction Pipeline
Preprocessing Steps
- Windowing: Divide audio into overlapping frames (typically 25ms with 10ms overlap)
- Pre-emphasis: Apply high-pass filter to emphasize higher frequencies
- Windowing Function: Apply Hamming or Hanning window to reduce spectral leakage
MFCC Computation
- FFT: Compute Fast Fourier Transform of windowed frames
- Power Spectrum: Calculate squared magnitude of FFT
- Mel Filter Bank: Apply triangular filters in mel scale
- Logarithm: Take log of filter bank energies
- DCT: Apply Discrete Cosine Transform to get MFCCs
Neural Network Architectures
Convolutional Neural Networks (CNNs)
CNNs are particularly effective for MFCC-based audio classification because they can capture local patterns and spatial relationships in the spectrogram-like MFCC features.
Recurrent Neural Networks (RNNs)
RNNs, especially LSTM and GRU variants, can model temporal dependencies in audio sequences, making them suitable for intent detection where context matters.
Hybrid Architectures
Combining CNNs for feature extraction with RNNs for sequence modeling often yields the best results for audio intent detection tasks.
Implementation with TensorFlow/Keras
Data Preprocessing
import librosa
import numpy as np
from sklearn.preprocessing import StandardScaler
def extract_mfcc_features(audio_file, n_mfcc=13, n_fft=2048, hop_length=512):
# Load audio file
y, sr = librosa.load(audio_file, sr=16000)
# Extract MFCC features
mfccs = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=n_mfcc,
n_fft=n_fft, hop_length=hop_length)
# Normalize features
mfccs = StandardScaler().fit_transform(mfccs.T)
return mfccs
CNN Model Architecture
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
def create_cnn_model(input_shape, num_classes):
model = Sequential([
Conv2D(32, (3, 3), activation='relu', input_shape=input_shape),
MaxPooling2D((2, 2)),
Conv2D(64, (3, 3), activation='relu'),
MaxPooling2D((2, 2)),
Conv2D(128, (3, 3), activation='relu'),
MaxPooling2D((2, 2)),
Flatten(),
Dense(512, activation='relu'),
Dropout(0.5),
Dense(num_classes, activation='softmax')
])
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
return model
Dataset: Fluent Speech Commands
The Fluent Speech Commands dataset is a popular benchmark for intent detection, containing:
- 30,043 utterances from 97 speakers
- 31 intent classes across 3 domains (action, object, location)
- Various speaking styles and acoustic conditions
- Balanced distribution across intent classes
Training Strategy
Data Augmentation
To improve model robustness, we applied several augmentation techniques:
- Time Stretching: Vary speech rate without changing pitch
- Pitch Shifting: Modify pitch while preserving duration
- Noise Addition: Add background noise at various SNR levels
- Speed Perturbation: Change playback speed
Training Configuration
- Batch size: 32
- Learning rate: 0.001 with exponential decay
- Epochs: 100 with early stopping
- Validation split: 20%
- Optimizer: Adam with beta1=0.9, beta2=0.999
Results and Analysis
Performance Metrics
Our MFCC-based approach achieved the following results on the Fluent Speech Commands dataset:
- Overall Accuracy: 94.2%
- F1-Score (Macro): 0.941
- F1-Score (Micro): 0.942
- Inference Time: 12ms per utterance
Confusion Matrix Analysis
Analysis of the confusion matrix revealed that the model performs well across most intent classes, with some confusion between semantically similar intents (e.g., "turn on" vs "turn off").
Comparison with Other Approaches
| Method | Features | Accuracy | Parameters |
|---|---|---|---|
| MFCC + CNN | 13 MFCCs | 94.2% | 2.1M |
| Raw Audio + CNN | Raw waveform | 92.8% | 3.4M |
| Spectrogram + CNN | Log-mel spectrogram | 93.5% | 2.8M |
| MFCC + LSTM | 13 MFCCs | 93.1% | 1.8M |
Practical Considerations
Real-time Processing
For real-time applications, consider:
- Streaming MFCC computation
- Model quantization for faster inference
- Sliding window approach for continuous audio
- Confidence thresholding for reliable predictions
Deployment Challenges
Common challenges in production deployment include:
- Handling different microphone qualities
- Managing background noise and echo
- Supporting multiple languages and accents
- Ensuring low-latency responses
Future Directions
Advanced Feature Extraction
Recent research explores alternatives to MFCCs:
- Mel-spectrograms: Higher resolution frequency representation
- Raw audio processing: End-to-end learning from waveforms
- Multi-scale features: Combining different time-frequency representations
Transformer-based Models
Transformer architectures are showing promising results in audio processing, potentially replacing traditional CNN-RNN combinations.
Conclusion
MFCC-based audio intent detection remains a robust and efficient approach for voice-controlled applications. While newer methods like raw audio processing and transformer models show promise, MFCCs offer an excellent balance between performance and computational efficiency. The key to success lies in proper feature extraction, appropriate model architecture selection, and comprehensive data augmentation strategies.
Project Links
References
1. Davis, S., & Mermelstein, P. "Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences." IEEE Transactions on Acoustics, Speech, and Signal Processing, 1980.
2. Fluent Speech Commands Dataset: https://fluent.ai/fluent-speech-commands/
3. Hershey, S., et al. "CNN architectures for large-scale audio classification." ICASSP 2017.
4. McFee, B., et al. "librosa: Audio and music signal analysis in python." SciPy 2015.