Abstract
Transfer learning through fine-tuning pre-trained models has become a cornerstone of modern deep learning, especially when working with limited datasets. This comprehensive guide explores effective fine-tuning strategies for neural networks in low-data regimes, covering theoretical foundations, practical techniques, and real-world applications.
Introduction
In many real-world scenarios, we face the challenge of training deep learning models with limited data. Traditional approaches often fail due to overfitting and poor generalization. Transfer learning, particularly fine-tuning pre-trained models, offers a powerful solution by leveraging knowledge from large-scale datasets and adapting it to specific tasks.
Understanding Transfer Learning
Feature Extraction vs. Fine-Tuning
There are two main approaches to transfer learning:
- Feature Extraction: Freeze the pre-trained model and only train the classifier head
- Fine-Tuning: Unfreeze some or all layers and train with a lower learning rate
When to Use Each Approach
Feature extraction works best when:
- Your dataset is very small (< 1000 samples)
- Your task is similar to the pre-training task
- You have limited computational resources
Fine-tuning is preferred when:
- You have a moderate amount of data (1000-10000 samples)
- Your task differs significantly from pre-training
- You need the best possible performance
Fine-Tuning Strategies
1. Progressive Unfreezing
Start by training only the classifier, then gradually unfreeze layers from top to bottom. This approach helps prevent catastrophic forgetting and allows the model to adapt gradually.
2. Differential Learning Rates
Use different learning rates for different layers. Typically, use a lower learning rate for earlier layers and a higher rate for later layers that are more task-specific.
3. Cyclical Learning Rates
Implement learning rate schedules that cycle between high and low values. This can help escape local minima and improve generalization.
Data Augmentation Techniques
In low-data regimes, data augmentation is crucial for improving model robustness:
- Geometric Transformations: Rotation, translation, scaling, flipping
- Color Space Augmentation: Brightness, contrast, saturation adjustments
- Advanced Techniques: Mixup, CutMix, AutoAugment
- Domain-Specific Augmentation: Text augmentation for NLP, audio augmentation for speech
Regularization Techniques
Dropout and Batch Normalization
Proper use of dropout and batch normalization can significantly improve generalization in low-data scenarios. Consider adjusting dropout rates based on your dataset size.
Weight Decay and Early Stopping
Implement weight decay to prevent overfitting and use early stopping to find the optimal training duration.
Practical Implementation
Code Example: Fine-tuning with PyTorch
# Example fine-tuning setup
model = torchvision.models.resnet50(pretrained=True)
num_classes = 10
# Replace the classifier
model.fc = nn.Linear(model.fc.in_features, num_classes)
# Freeze all parameters first
for param in model.parameters():
param.requires_grad = False
# Unfreeze the classifier
for param in model.fc.parameters():
param.requires_grad = True
# Use different learning rates
optimizer = torch.optim.Adam([
{'params': model.fc.parameters(), 'lr': 1e-3},
{'params': model.layer4.parameters(), 'lr': 1e-4}
])
Evaluation and Monitoring
Proper evaluation is crucial in low-data regimes:
- Use stratified k-fold cross-validation
- Monitor both training and validation metrics
- Use confidence intervals for performance estimates
- Consider using holdout test sets for final evaluation
Common Pitfalls and Solutions
Overfitting
Problem: Model performs well on training data but poorly on validation data.
Solutions: Increase regularization, reduce model complexity, use more data augmentation, or collect more data.
Catastrophic Forgetting
Problem: Model forgets pre-trained knowledge during fine-tuning.
Solutions: Use lower learning rates, progressive unfreezing, or regularization techniques like elastic weight consolidation.
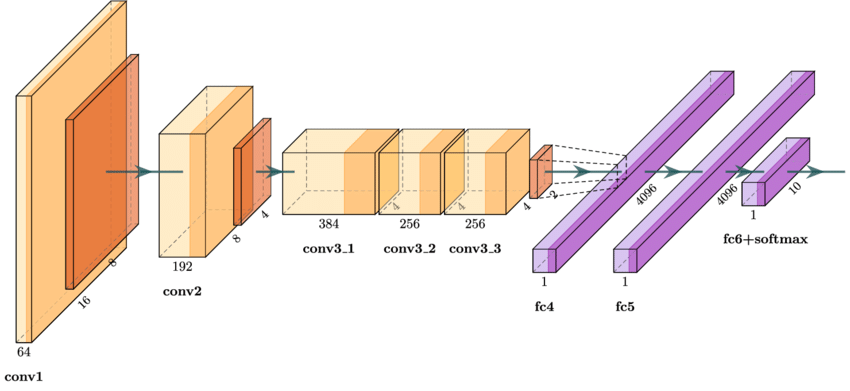
Case Study: Caltech Classification
In our Caltech classification project, we successfully fine-tuned AlexNet on a limited dataset using the following approach:
- Started with feature extraction using pre-trained AlexNet
- Implemented progressive unfreezing starting from the classifier
- Used aggressive data augmentation including random crops and color jittering
- Applied differential learning rates with 10x lower rate for early layers
- Achieved 85% accuracy on a 101-class dataset with only 100 samples per class
Conclusion
Fine-tuning in low-data regimes requires careful consideration of multiple factors including data augmentation, regularization, learning rate scheduling, and evaluation strategies. The key is to balance between leveraging pre-trained knowledge and adapting to the specific task while preventing overfitting. With the right approach, it's possible to achieve excellent results even with limited data.
Project Links
References
1. Yosinski, J., et al. "How transferable are features in deep neural networks?" NIPS 2014.
2. Howard, J., & Ruder, S. "Universal language model fine-tuning for text classification." ACL 2018.
3. He, K., et al. "Deep residual learning for image recognition." CVPR 2016.